本文共 8120 字,大约阅读时间需要 27 分钟。

设为“置顶或星标”,第一时间送达干货。
前言
当下互联网行业最火的技术被称为ABC,即 AI人工智能 、 BigData大数据 、 Cloud云计算平台 。当然也许还会提到区块链技术以及最近央行试行的数字货币等。A和C属于高级技能,一般公司不需要也不易掌握,对于B还是比较平民化的,大大小小的公司借助开源技术栈都可以参与其中。
为什么是Kafka?
Kafka目前最新版本:2.6.0。
2.6.0 is the latest release. The current stable version is 2.6.0.
作为工程师或架构师,在实际工作过程中一定参与到了很多 大数据业务系统的构建 。由于这些系统都是 为公司业务服务的 ,所以通常来说它们仅仅是执行一些常规的业务逻辑,因此它们 不能算是计算密集型应用,相反更应该是数据密集型的 。
对于数据密集型应用来说,如何应对 数据量激增、数据复杂度增加以及数据变化速率变快 ,是彰显大数据工程师、架构师功力的最有效表征。在实际的工程实践中,我们发现Kafka在帮助我们应对这些问题方面能起到非常好的效果。就拿数据量激增来说,Kafka能够有效隔离上下游业务,将上游突增的流量缓存起来,以平滑的方式传导到下游子系统中,避免了流量的不规则冲击。由此可见, 作为一名大数据从业人员,熟练掌握Kafka是非常必要的一项技能 。
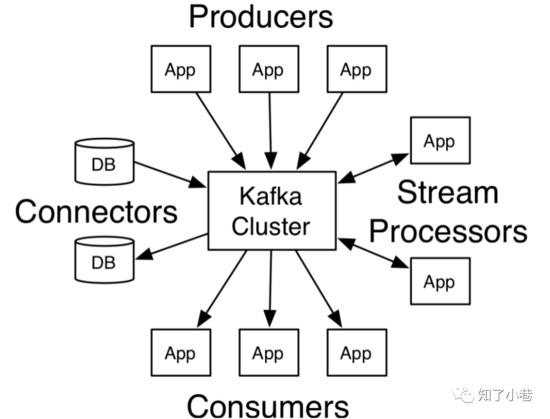
事实上,Kafka有着非常广泛的应用场景。在业界,目前Apache Kafka被认为是整个消息引擎领域的盟主,仅凭这一点就值得我们好好学习和掌握它。我们仅需要学习一套框架就能在实际业务系统中实现 消息引擎应用 、 应用程序集成 、 分布式存储构建
,甚至是
流处理应用
的开发与部署。
2019年两会上再一次提到了要深化大数据、人工智能等领域应用的研发和发展,而Kafka无论是作为消息引擎还是实时流处理平台,都能在大数据工程领域发挥重要的作用。
如何学习Kafka?
掌握Kafka的第一步就是要根据你掌握的编程语言去寻找对应的 Kafka客户端 。当前Kafka最重要的两大客户端是 Java客户端和libkafka客户端 ,它们更新和维护的速度很快,非常适合我们持续花时间投入。
https://github.com/edenhill/librdkafka
- 确定了要使用的客户端,马上去官网上学习一下代码示例,如果能够正确编译和运行这些样例,就能轻松地驾驭客户端了。
- 比如Java客户端:http://kafka.apache.org/24/documentation.html#api
Maven Dependency:
org.apache.kafka kafka-clients 2.6.0
Producer demo代码:
package kafka;import java.util.Properties;import java.util.concurrent.Future;import org.apache.kafka.clients.producer.Callback;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;import org.apache.kafka.common.serialization.StringSerializer;public class Producer { public static void main(String[] args) { Properties properties = new Properties(); // bootstrap.servers kafka集群地址 host1:port1,host2:port2 .... properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092"); // key.deserializer 消息key序列化方式 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value.deserializer 消息体序列化方式 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); KafkaProducer producer = new KafkaProducer<>(properties); // 0 异步发送消息 for (int i = 0; i < 10; i++) { String data = "async :" + i; // 发送消息 producer.send(new ProducerRecord<>("demo-topic", data)); } // 1 同步发送消息 调用get()阻塞返回结果 for (int i = 0; i < 10; i++) { String data = "sync : " + i; try { // 发送消息 Future send = producer.send(new ProducerRecord<>("demo-topic", data)); RecordMetadata recordMetadata = send.get(); System.out.println(recordMetadata); } catch (Exception e) { e.printStackTrace(); } } // 2 异步发送消息 回调callback() for (int i = 0; i < 10; i++) { String data = "callback : " + i; // 发送消息 producer.send(new ProducerRecord<>("demo-topic", data), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { // 发送消息的回调 if (exception != null) { exception.printStackTrace(); } else { System.out.println(metadata); } } }); } producer.close(); }} Consumer端demo代码:
package kafka;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;import java.util.Arrays;import java.util.Properties;public class Consumer { public static void main(String[] args) { Properties properties = new Properties(); //bootstrap.servers kafka集群地址 host1:port1,host2:port2 .... properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092"); // key.deserializer 消息key序列化方式 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // value.deserializer 消息体序列化方式 properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // group.id 消费组id properties.put(ConsumerConfig.GROUP_ID_CONFIG, "demo-group"); // enable.auto.commit 设置自动提交offset properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); // auto.offset.reset properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); KafkaConsumer consumer = new KafkaConsumer<>(properties); String[] topics = new String[]{"demo-topic"}; consumer.subscribe(Arrays.asList(topics)); while (true) { ConsumerRecords records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord record : records) { System.out.println(record); } } }} Libkafka examples:
https://github.com/edenhill/librdkafka/tree/master/examples
可能会用到Python的kafka客户端:
https://github.com/Parsely/pykafka
安装pykafka客户端模块
$ pip install pykafka
初始化客户端对象
>>> from pykafka import KafkaClient>>> client = KafkaClient(hosts="127.0.0.1:9092,127.0.0.1:9093,...")
TLS(https连接)
>>> from pykafka import KafkaClient, SslConfig>>> config = SslConfig(cafile='/your/ca.cert',... certfile='/your/client.cert', # optional... keyfile='/your/client.key', # optional... password='unlock my client key please') # optional>>> client = KafkaClient(hosts="127.0.0.1:,...",... ssl_config=config)
监听topic
>>> client.topics>>> topic = client.topics['my.test']
往topic发送消息,这里是同步发送的,需要等待消息确认才能发送下一条
>>> with topic.get_sync_producer() as producer:... for i in range(4):... producer.produce('test message ' + str(i ** 2)) 为了提高吞吐量, 推荐Producer采用异步发送消息模式 ,produce()函数被调用后会立即返回
>>> with topic.get_producer(delivery_reports=True) as producer:... count = 0... while True:... count += 1... producer.produce('test msg', partition_key='{}'.format(count))... if count % 10 ** 5 == 0: # adjust this or bring lots of RAM ;)... while True:... try:... msg, exc = producer.get_delivery_report(block=False)... if exc is not None:... print 'Failed to deliver msg {}: {}'.format(... msg.partition_key, repr(exc))... else:... print 'Successfully delivered msg {}'.format(... msg.partition_key)... except Queue.Empty:... break Consumer消费topic里的消息
>>> consumer = topic.get_simple_consumer()>>> for message in consumer:... if message is not None:... print message.offset, message.value0 test message 01 test message 12 test message 43 test message 9
负载均衡的Consumer-BalancedConsumer
>>> balanced_consumer = topic.get_balanced_consumer(... consumer_group='testgroup',... auto_commit_enable=True,... zookeeper_connect='myZkClusterNode1.com:2181,myZkClusterNode2.com:2181/myZkChroot'... )
PyKafka里面含有C扩展库,可以使用librdkafka来加速Producer和Consumer的一些操作。
- 下一步就可以尝试修改样例代码尝试去理解并使用其他的API,之后观测修改样例代码后的执行结果。如果这些都难不倒我们,接着就可以自己编写一个小型项目来验证下学习成果,然后就是改善和提升客户端的可靠性和性能了。到了这一步,后面就可以熟读一遍Kafka官网文档,确保理解了那些可能影响可靠性和性能的参数。
- 最后是学习Kafka的高级功能,比如流处理应用开发。流处理 API 不仅能够生产和消费消息,还能执行高级的流式处理操作,比如时间窗口聚合、流处理连接等。
对于一个系统管理员或运维工程师,相应的学习目标应该是学习搭建及管理Kafka线上环境。如何根据实际业务需求评估、搭建生产线上环境将是主要的学习目标。另外对生产环境的监控也是重中之重的工作,Kafka 提供了超多的JMX监控指标,可以选择任意熟知的框架进行监控,比如Kafka-Eagle。
https://github.com/smartloli/kafka-eagle
Kafka需要掌握的核心内容
- 消息引擎这类系统大致的原理和用途,以及作为优秀消息引擎代表的Kafka在这方面的表现。
- Kafka如何用于生产环境,特别是线上环境方案的制定。
- Kafka客户端的方方面面,包含生产者和消费者原理与实践。
- Kafka最核心的设计原理,包括Controller的设计机制、请求处理全流程解析等。
- Kafka运维与监控的内容,高效运维Kafka集群以及有效监控Kafka的实战
转载地址:http://hsgii.baihongyu.com/